Like Apple M1 chip and neural network acceralators, Custom-Processor and Domain-Specific Architecture are developed worldwide, including major IT companies.
The hardware optimized for the process users want is very excellent in high speed and low power consumption. From CPU to AI and IoT, the demand for custom processors is increasing, and rapid designing is required. However, it requires advanced knowledge, skills, and high cost prototype hardware.
This Lab is developing "C2RTL" that directly converts processor's dataflow written in C/C++ to RTL.
Characteristics of C2RTL is:
1.
Dataflow inc C/C++ directly converted to RTL of custom processor
2.
Because of cycle-level description, generated processors work exactly what designers want,
and users can easily represent and implement super-paralleled process like Deep Learning.
3.
HW simulation runs on SW makes debugging easy and low-cost.
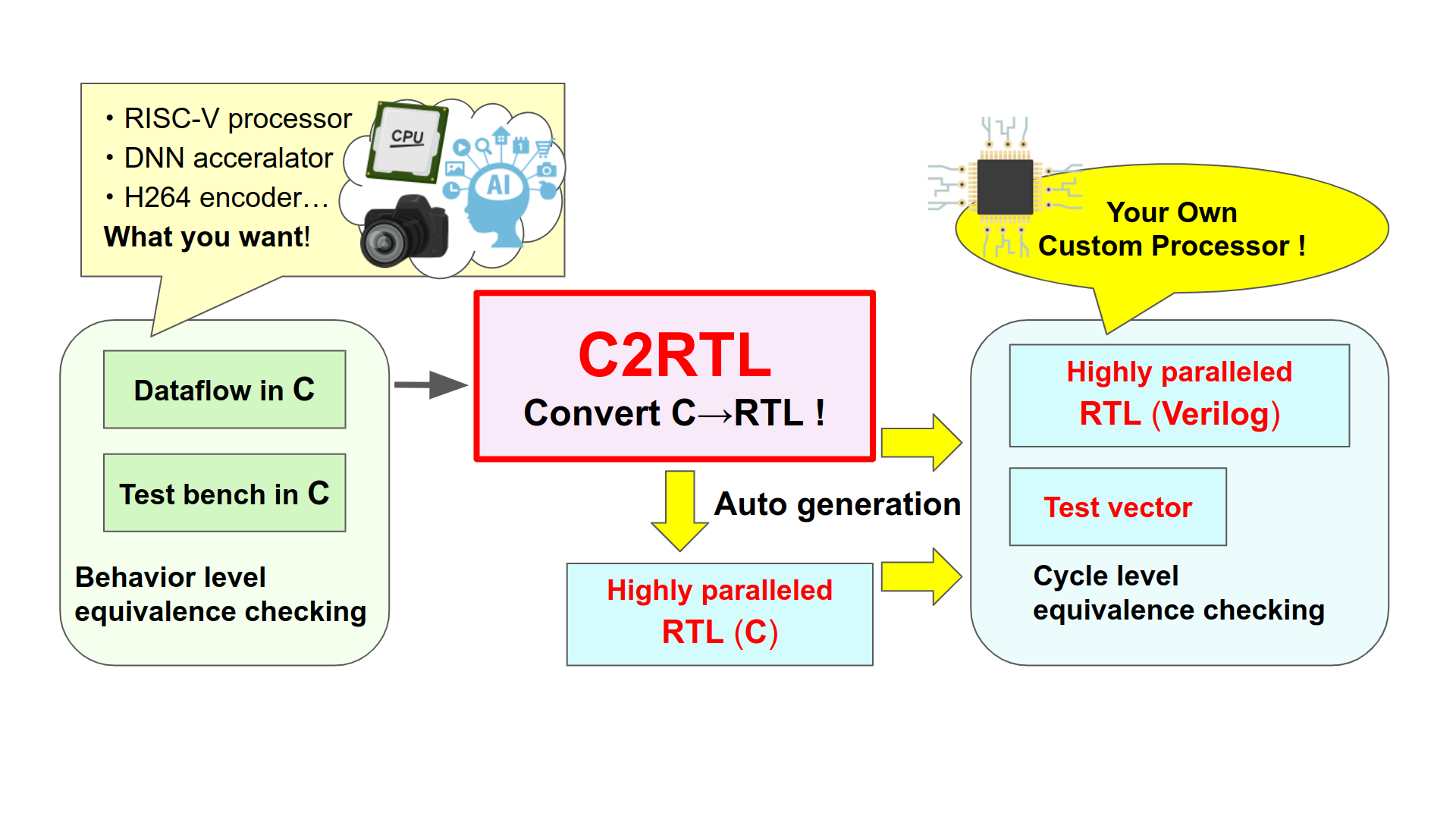
C2RTL is in cycle-level description like explicit FSM that is the same level of abstraction to RTL. In general high level synthesis, writing method and inner-process are different for each tool, so you need to be familiar with tools to generate high-quality RTL. Since the cycle-level description of C2RTL works from SW to HW exactly as the designer intended, it is possible to design with grasping the inside of system and without any black box.
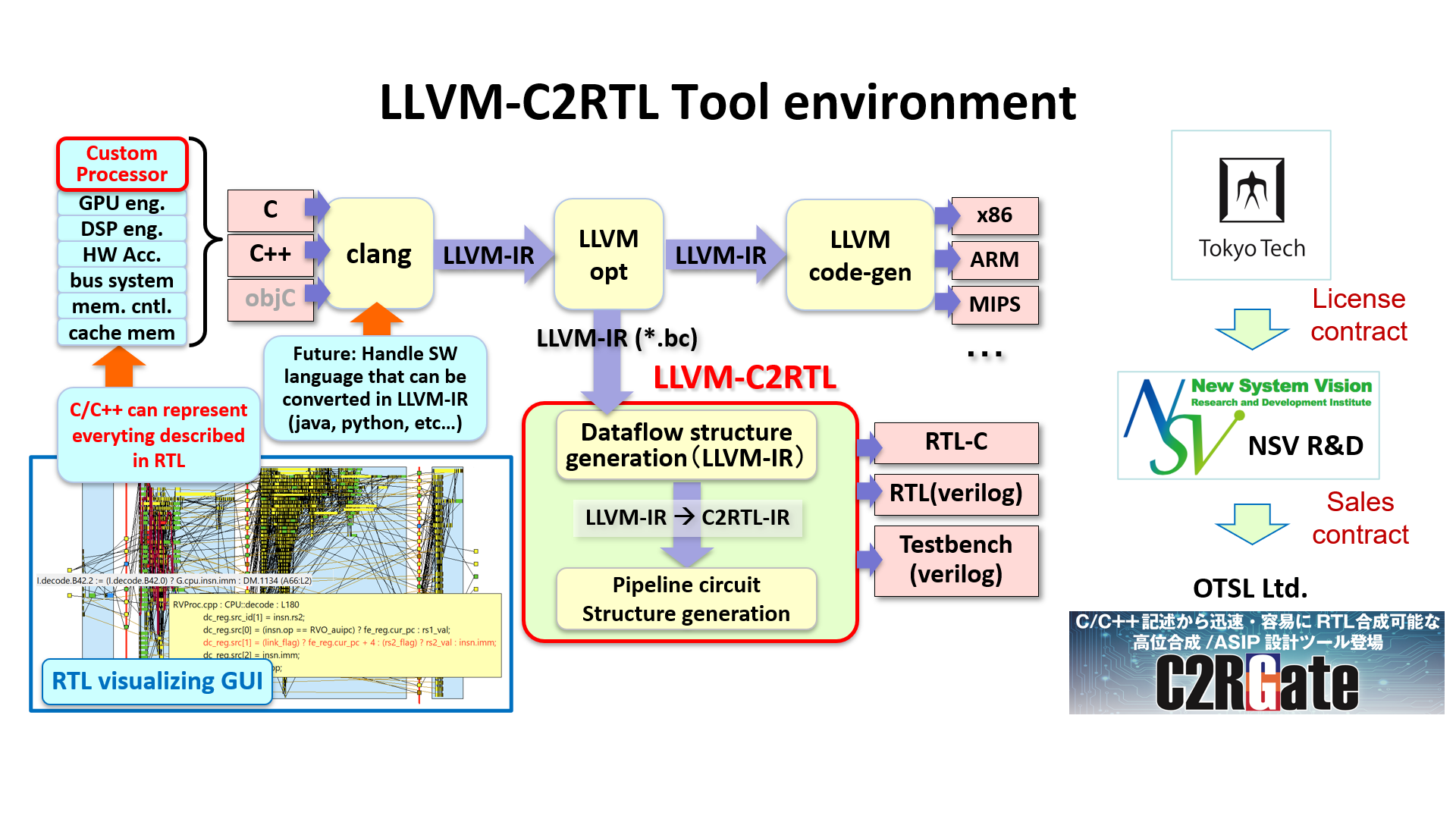
Further, C2RTL uses LLVM, so it can convert C/C++ design not only to RTL, but also x86 and Arm formats. This offers advanced cooperation with outside C2RTL, it enables creating expanded functions and debugging easily.
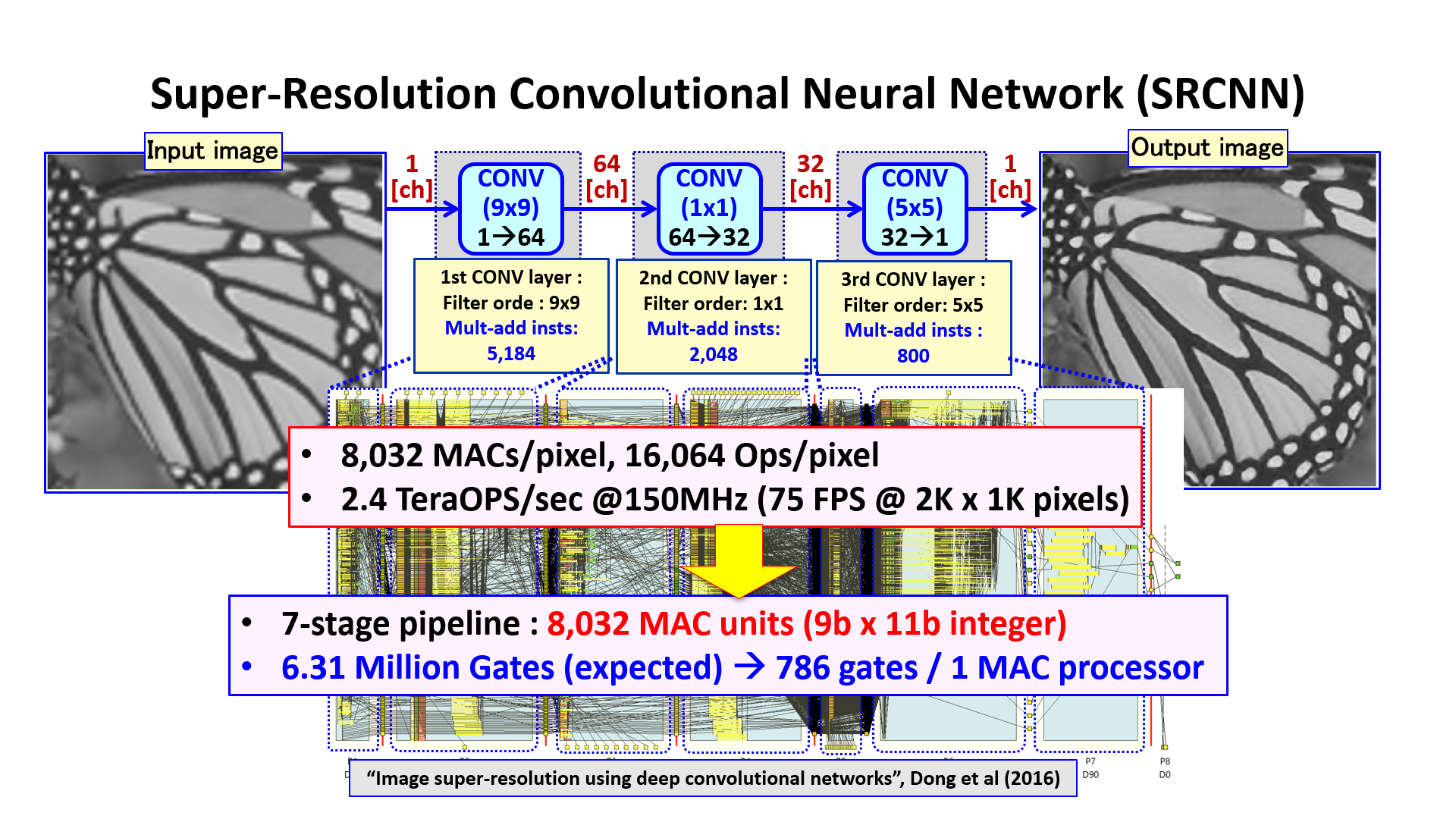
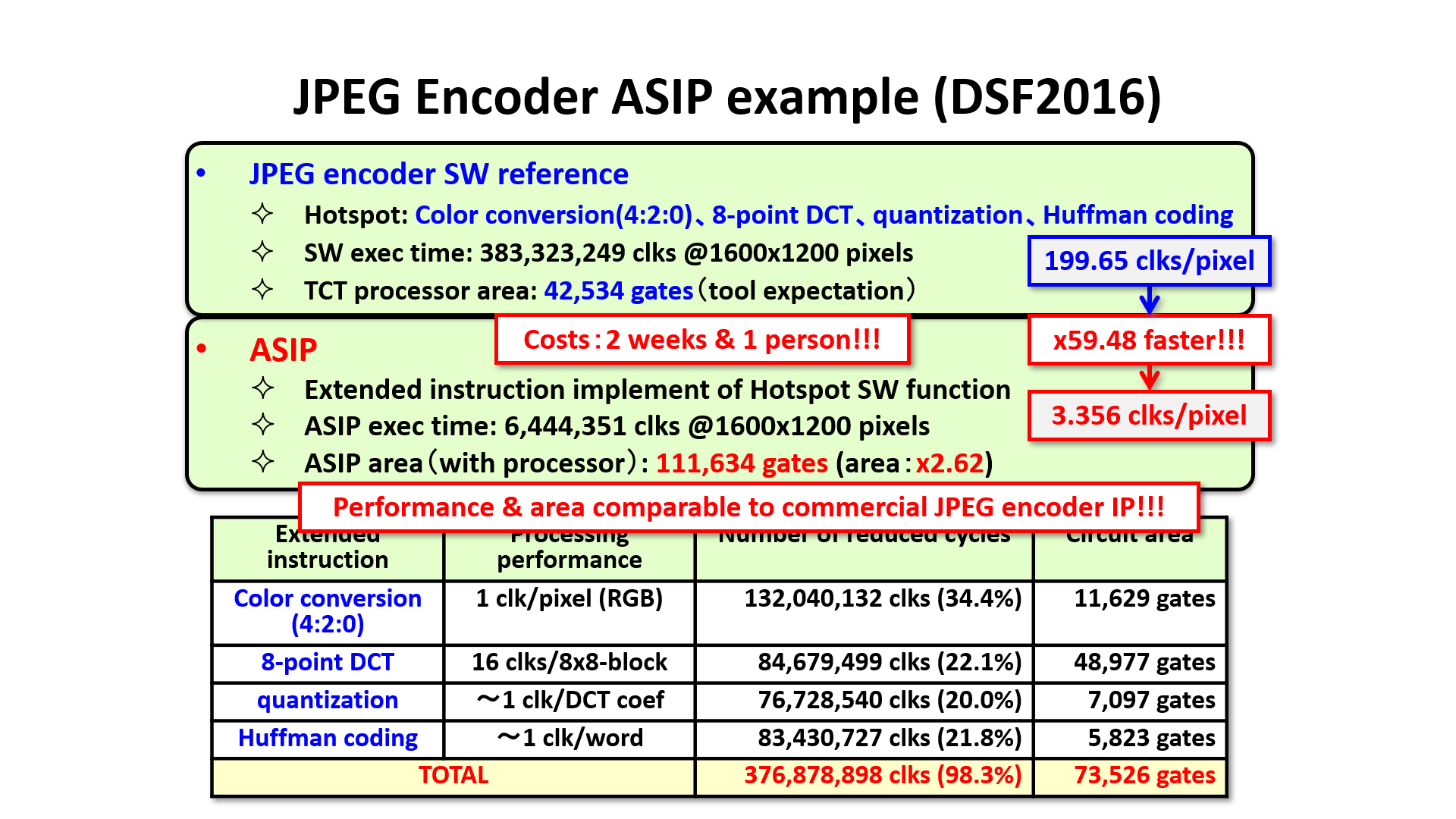
We created super-resolution 3 layer comvolutional neural network that has 2 stages pipeline and 8032 multiply-add units, and it achieved 2.4TereOps/sec in 150MHz operating frequency. Also, JPEG encoder comparable to commercial IP is created by 1 person and 2 weeks.
And more, we've created HW fingerprint recognition and DNN networks like these.
RISC-V, an open source architecture that anyone can use for free and implement custom instructions, is a technology that attracts atttention since AI, IoT and custom processors is developing.
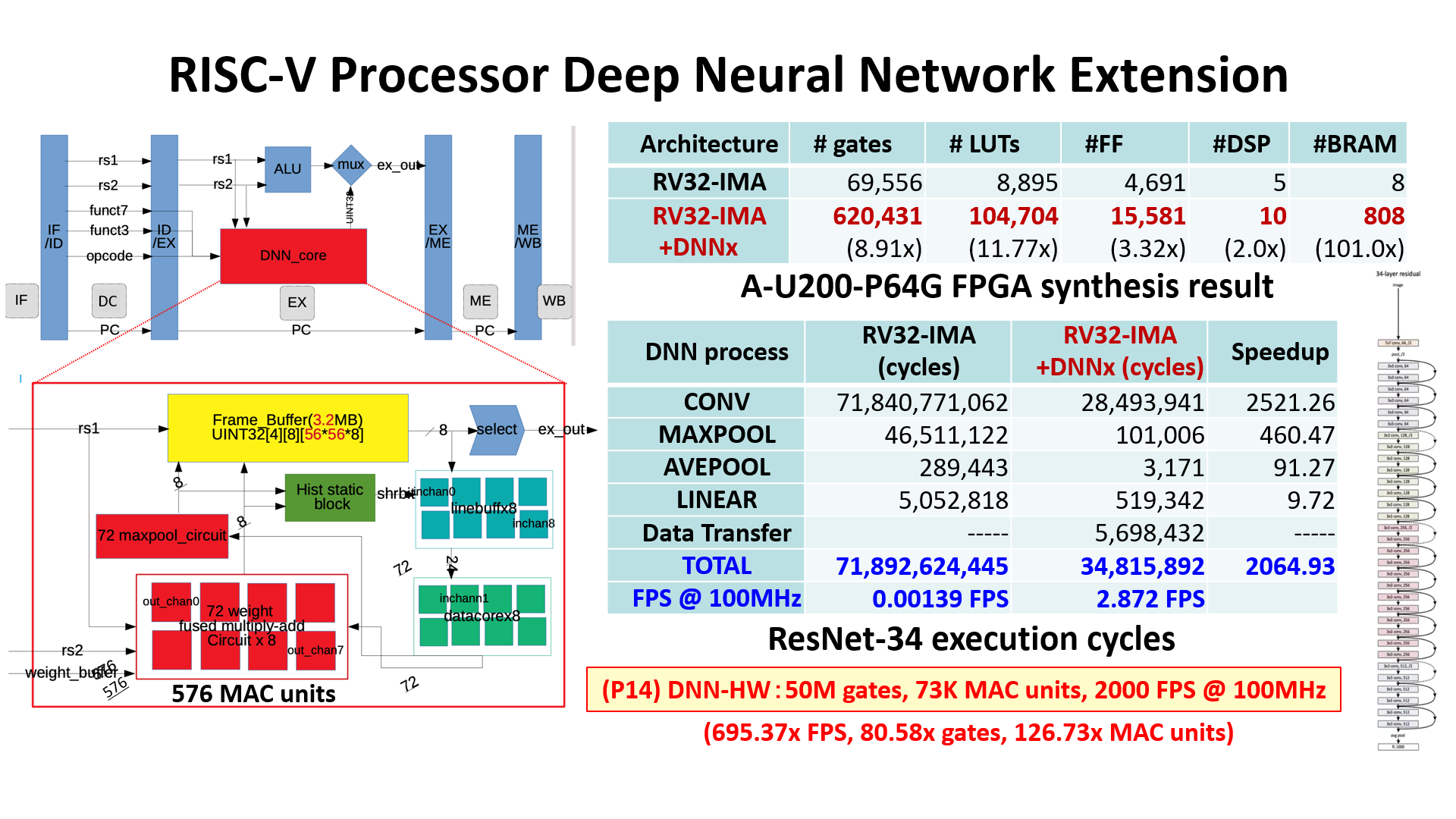
This Lab researches RISC-V processors that has advanced functions with utilizing C2RTL. It supports RV32/64 and is implemented MMU/Cache, so on which Linux can runs. Further, FPU and DNN acceralator are implemented. This HW DNN acceralator executes the DNN 700 times faster than simple SW execution.
Now, we've implementing vector processor, 16bit compressed instructions, multi-processor and so on.
Like Apple M1 chip and neural network acceralators, Custom-Processor and Domain-Specific Architecture are developed worldwide, including major IT companies.
The hardware optimized for the process users want is very excellent in high speed and low power consumption. From CPU to AI and IoT, the demand for custom processors is increasing, and rapid designing is required. However, it requires advanced knowledge, skills, and high cost prototype hardware.
This Lab is developing "C2RTL" that directly converts processor's dataflow written in C/C++ to RTL.
Characteristics of C2RTL is:
1.
Dataflow inc C/C++ directly converted to RTL of custom processor
2.
Because of cycle-level description, generated processors work exactly what designers want,
and users can easily represent and implement super-paralleled process like Deep Learning.
3.
HW simulation runs on SW makes debugging easy and low-cost.
C2RTL is in cycle-level description like explicit FSM that is the same level of abstraction to RTL. In general high level synthesis, writing method and inner-process are different for each tool, so you need to be familiar with tools to generate high-quality RTL. Since the cycle-level description of C2RTL works from SW to HW exactly as the designer intended, it is possible to design with grasping the inside of system and without any black box.
Further, C2RTL uses LLVM, so it can convert C/C++ design not only to RTL, but also x86 and Arm formats. This offers advanced cooperation with outside C2RTL, it enables creating expanded functions and debugging easily.
We created super-resolution 3 layer comvolutional neural network that has 2 stages pipeline and 8032 multiply-add units, and it achieved 2.4TereOps/sec in 150MHz operating frequency. Also, JPEG encoder comparable to commercial IP is created by 1 person and 2 weeks.
And more, we've created HW fingerprint recognition and DNN networks like these.
RISC-V, an open source architecture that anyone can use for free and implement custom instructions, is a technology that attracts atttention since AI, IoT and custom processors is developing.
This Lab researches RISC-V processors that has advanced functions with utilizing C2RTL. It supports RV32/64 and is implemented MMU/Cache, so on which Linux can runs. Further, FPU and DNN acceralator are implemented. This HW DNN acceralator executes the DNN 700 times faster than simple SW execution.
Now, we've implementing vector processor, 16bit compressed instructions, multi-processor and so on.
Like Apple M1 chip and neural network acceralators, Custom-Processor and Domain-Specific Architecture are developed worldwide, including major IT companies.
The hardware optimized for the process users want is very excellent in high speed and low power consumption. From CPU to AI and IoT, the demand for custom processors is increasing, and rapid designing is required. However, it requires advanced knowledge, skills, and high cost prototype hardware.
This Lab is developing "C2RTL" that directly converts processor's dataflow written in C/C++ to RTL.
Characteristics of C2RTL is:
1.
Dataflow inc C/C++ directly converted to RTL of custom processor
2.
Because of cycle-level description, generated processors work exactly what designers want,
and users can easily represent and implement super-paralleled process like Deep Learning.
3.
HW simulation runs on SW makes debugging easy and low-cost.
C2RTL is in cycle-level description like explicit FSM that is the same level of abstraction to RTL. In general high level synthesis, writing method and inner-process are different for each tool, so you need to be familiar with tools to generate high-quality RTL. Since the cycle-level description of C2RTL works from SW to HW exactly as the designer intended, it is possible to design with grasping the inside of system and without any black box.
Further, C2RTL uses LLVM, so it can convert C/C++ design not only to RTL, but also x86 and Arm formats. This offers advanced cooperation with outside C2RTL, it enables creating expanded functions and debugging easily.
We created super-resolution 3 layer comvolutional neural network that has 2 stages pipeline and 8032 multiply-add units, and it achieved 2.4TereOps/sec in 150MHz operating frequency. Also, JPEG encoder comparable to commercial IP is created by 1 person and 2 weeks.
And more, we've created HW fingerprint recognition and DNN networks like these.
RISC-V, an open source architecture that anyone can use for free and implement custom instructions, is a technology that attracts atttention since AI, IoT and custom processors is developing.
This Lab researches RISC-V processors that has advanced functions with utilizing C2RTL. It supports RV32/64 and is implemented MMU/Cache, so on which Linux can runs. Further, FPU and DNN acceralator are implemented. This HW DNN acceralator executes the DNN 700 times faster than simple SW execution.
Now, we've implementing vector processor, 16bit compressed instructions, multi-processor and so on.
Like Apple M1 chip and neural network acceralators, Custom-Processor and Domain-Specific Architecture are developed worldwide, including major IT companies.
The hardware optimized for the process users want is very excellent in high speed and low power consumption. From CPU to AI and IoT, the demand for custom processors is increasing, and rapid designing is required. However, it requires advanced knowledge, skills, and high cost prototype hardware.
This Lab is developing "C2RTL" that directly converts processor's dataflow written in C/C++ to RTL.
Characteristics of C2RTL is:
1.
Dataflow inc C/C++ directly converted to RTL of custom processor
2.
Because of cycle-level description, generated processors work exactly what designers want,
and users can easily represent and implement super-paralleled process like Deep Learning.
3.
HW simulation runs on SW makes debugging easy and low-cost.
C2RTL is in cycle-level description like explicit FSM that is the same level of abstraction to RTL. In general high level synthesis, writing method and inner-process are different for each tool, so you need to be familiar with tools to generate high-quality RTL. Since the cycle-level description of C2RTL works from SW to HW exactly as the designer intended, it is possible to design with grasping the inside of system and without any black box.
Further, C2RTL uses LLVM, so it can convert C/C++ design not only to RTL, but also x86 and Arm formats. This offers advanced cooperation with outside C2RTL, it enables creating expanded functions and debugging easily.
We created super-resolution 3 layer comvolutional neural network that has 2 stages pipeline and 8032 multiply-add units, and it achieved 2.4TereOps/sec in 150MHz operating frequency. Also, JPEG encoder comparable to commercial IP is created by 1 person and 2 weeks.
And more, we've created HW fingerprint recognition and DNN networks like these.
RISC-V, an open source architecture that anyone can use for free and implement custom instructions, is a technology that attracts atttention since AI, IoT and custom processors is developing.
This Lab researches RISC-V processors that has advanced functions with utilizing C2RTL. It supports RV32/64 and is implemented MMU/Cache, so on which Linux can runs. Further, FPU and DNN acceralator are implemented. This HW DNN acceralator executes the DNN 700 times faster than simple SW execution.
Now, we've implementing vector processor, 16bit compressed instructions, multi-processor and so on.
Like Apple M1 chip and neural network acceralators, Custom-Processor and Domain-Specific Architecture are developed worldwide, including major IT companies.
The hardware optimized for the process users want is very excellent in high speed and low power consumption. From CPU to AI and IoT, the demand for custom processors is increasing, and rapid designing is required. However, it requires advanced knowledge, skills, and high cost prototype hardware.
This Lab is developing "C2RTL" that directly converts processor's dataflow written in C/C++ to RTL.
Characteristics of C2RTL is:
1. Dataflow inc C/C++ directly converted to RTL of custom processor
2. Because of cycle-level description, generated processors work exactly what designers want,
and users can easily represent and implement super-paralleled process like Deep Learning.
3.
HW simulation runs on SW makes debugging easy and low-cost
.
C2RTL is in cycle-level description like explicit FSM that is the same level of abstraction to RTL. In general high level synthesis, writing method and inner-process are different for each tool, so you need to be familiar with tools to generate high-quality RTL. Since the cycle-level description of C2RTL works from SW to HW exactly as the designer intended, it is possible to design with grasping the inside of system and without any black box.
Further, C2RTL uses LLVM, so it can convert C/C++ design not only to RTL, but also x86 and Arm formats. This offers advanced cooperation with outside C2RTL, it enables creating expanded functions and debugging easily.
We created super-resolution 3 layer comvolutional neural network that has 2 stages pipeline and 8032 multiply-add units, and it achieved 2.4TereOps/sec in 150MHz operating frequency. Also, JPEG encoder comparable to commercial IP is created by 1 person and 2 weeks.
And more, we've created HW fingerprint recognition and DNN networks like these.
RISC-V, an open source architecture that anyone can use for free and implement custom instructions, is a technology that attracts atttention since AI, IoT and custom processors is developing.
This Lab researches RISC-V processors that has advanced functions with utilizing C2RTL. It supports RV32/64 and is implemented MMU/Cache, so on which Linux can runs. Further, FPU and DNN acceralator are implemented. This HW DNN acceralator executes the DNN 700 times faster than simple SW execution.
Now, we've implementing vector processor, 16bit compressed instructions, multi-processor and so on.
created with
Website Builder Software .